In a recent conversation based on a LinkedIn post, someone asked “Why choose a taxonomy over an ontology?” This is a good question, since there has been a growing understanding that ontologies build upon taxonomies by adding more semantics, which enable additional benefits. I have presented at conferences on the topic of extending a taxonomy with an ontology. Taxonomies, however, have benefits that ontologies alone cannot provide.
I have compared taxonomies and ontologies in a past blog post (Taxonomies vs. Ontologies). Comparing their uses to taxonomies, ontologies support more complex multi-part searches, enable searching on data and not just content or full documents, and can connect across data in different repositories and sources, which leads to creating knowledge graphs or a semantic layer. Additionally, ontologies support modeling and exploration of complex relationships, graph visualizations, and support for reasoning and inferencing based on logic. Meanwhile, ontologies also include the basic feature of taxonomies of unlimited hierarchies of classes and subclasses. Thus, it may seem as if ontologies are superior to taxonomies and provide greater benefits than taxonomies.

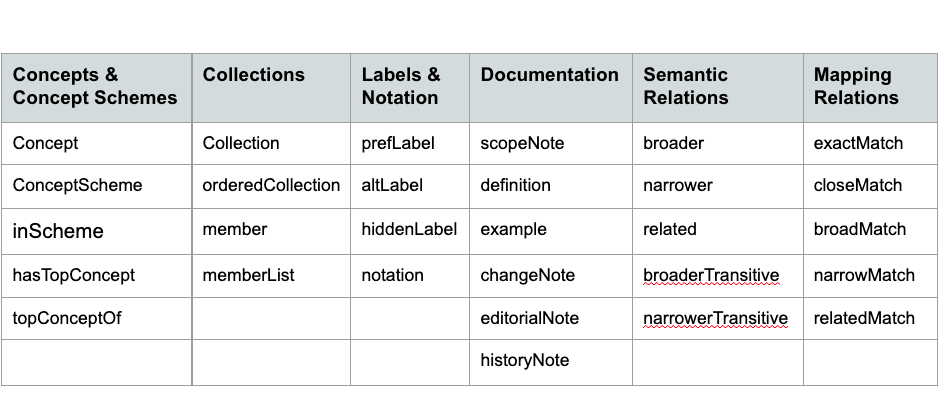
Taxonomies are richer than ontologies in their linguistic aspects, including both synonyms and labels in other languages. Taxonomies are traditionally based on thesauri, which include the feature of having “equivalence” among multiple terms, whereby a preferred term may be “used for” other nonpreferred terms. The SKOS data model specifies a preferred label and any number of alternative labels and hidden labels for a concept. Furthermore, concepts may have labels in multiple languages, and this supports tagging content in different languages and retrieval by users of different languages.
In ontologies, there exists the OWL property of sameAs for equivalence of individuals and equivalentClass for equivalence of classes, but both tend to be used to declare equivalence across different datasets rather than for use within a single ontology, as there is no designation of preferred and alternative names. So, these OWL properties are more like mapping properties than support of synonyms within a controlled vocabulary. As such they do not support the basic purpose of alternative labels in a taxonomy, which is to enable matches to support searching on variant labels and tagging despite different words in texts for the same thing.
The SKOS data model for taxonomies defines properties for scope notes, editorial notes, history notes, examples, and definitions. These are standardized fields and thus the meanings of these notes fields are consistent across taxonomies, supporting interoperability and migration. In OWL ontologies there exists an annotation property, but its use broadly includes labels, definitions, synonyms, attribution, notes, or comments. With such inconsistent use, annotations are not well supported in importing, exporting, or linking of ontologies.
SKOS also has a set of mapping relationships. While OWL supports equivalence with SameAs and equivalentClass, SKOS taxonomies have not only equivalence relationships, exactMatch, but also closeMatch, narrowMatch, broadMatch, and relatedMatch, and thus all concepts in two separate taxonomies can be mapped to each other, unlike two ontologies which may share only a few matches. The full mapping of one taxonomy for another supports various uses, including using one taxonomy in the front end and the other in the back end, tagged to content.
Finally, taxonomies are better suited for various content-based implementation and applications, especially with out-of-the-box systems, such web content management systems, digital asset management systems, SharePoint, etc. A taxonomy modeled is several SKOS concept schemes can designate each concept scheme as a facet in faceted search/browse system, in which a facet serves as a filter. A taxonomy built as a hierarchy tree can be implemented so that users can expand the tree to browse to narrower concepts and then they can retrieve content tagged with the most specific concept desired. Ontologies, even if they contain hierarchies of classes and subclasses, are typically visualized as graphs, and any hierarchies are not displayed in a front-end application. Furthermore, ontology visualizations are usually not linked to actual content or data as they serve just for visualizing.
In sum, while ontologies add richer semantics/ meaning to relationships and attributes, taxonomies have richer semantics/meaning for concepts. Combining a taxonomy and ontology can bring the best of both worlds, and semantic web standards of SKOS, OWL, and RDF-S are all compatible for combining within a single project, since they are all based on the RDF (Resource Description Framework) data model. However, in many cases, a taxonomy with rich meaning for concepts, support for synonyms in search and tagging, along interactive displays of hierarchies and/or facets, is all that is needed. You can always add an ontology later.