Over the 26 years that I have been involved in controlled
vocabularies, thesauri, and taxonomies, the biggest change I have seen in the
field is the adoption of SKOS (Simple Knowledge Organization System) as a schema
model and standard.
If you are creating taxonomies exclusively within a single
system (such as the SharePoint Term Store or controlled tags or categories of a
content management system, documentation management system, DAM, etc.), then
you probably have not paid much attention to SKOS. It’s true that taxonomies
created within and used within a single system, do not have to follow an
external standard. But that is not the trend of information management and
technology anymore. Connectivity, interoperability, data sharing and reuse,
data-centric architecture, vendor-neutral formats, linked data and linked open
data, breaking down data silos, enterprise-wide knowledge, and enterprise
knowledge graphs have become the preferred trends and directions.
Different Kinds of Standard
With respect to standards, there exist two basic kinds: (1) standards
for design, functionality, and a consistent user experience, and (2) standards
for compatibility, interoperability, and machine-readability. For this reason,
there are two separate sets of standards for taxonomies and other knowledge
organization systems. Another way to think of it is that there are standards
for each the front end (user interface and experience) and the back end
(computer-readable code) of taxonomies, and they are somewhat independent yet
still compatible with each other.
For taxonomies and thesauri, more has been written about the
front-end design and best practice standards than the back-end interoperability
standards. This is for several reasons. The design and best practices standards
(ANSI/NISO Z39.19 and ISO 25964 and its predecessors ISO 2788 and ISO 5964),
have been around longer. They are lengthier and more detailed than interoperability
standards, and they apply to taxonomies and thesauri regardless of their
digital or nondigital format. So, this article will focus instead on the
back-end, interoperability standard, which is SKOS.
SKOS Background
SKOS is a recommendation for "a common data model for
sharing and linking knowledge organization systems via the Semantic Web".
These knowledge organization systems include thesauri (as defined by the
ANSI/NISO and ISO thesaurus standards), taxonomies, classification schemes,
subject heading systems, and other controlled vocabularies. SKOS is based on
RDF (Resource Description Framework), a World Wide Web Consortium (W3C)
standard for description and exchange of graph data. RDF specifies that all statements
consist of subject-predicate-object triples, and all resources have URIs (uniform
resource identifiers).
The development of SKOS aimed to build upon RDF to provide a recommended
schema for thesauri. SKOS development
was first undertaken as the Semantic Web Advanced Development for Europe
(SWAD-Europe) project before being adopted and supported by the W3C in 2004.
The W3C formally released the SKOS recommendation in 2009.
Meanwhile, the W3C had been working on other recommendations
for web-based ontologies, including RDF Schema (RDFS) and Web Ontology Language(OWL). SKOS is compatible with RDFS and OWL, and elements from the different
models can be combined. Furthermore, SKOS can even be considered as a very
generic upper ontology itself, and the W3C documentation describes SKOS in
terms of OWL and RDFS expressions.
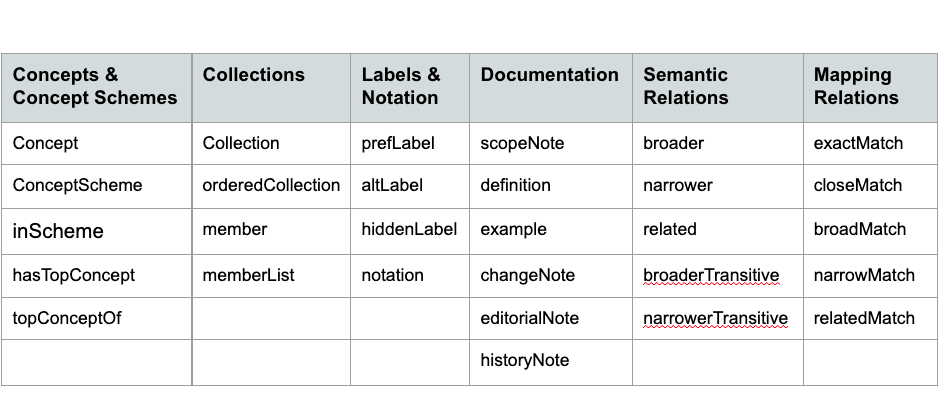
The main types of elements of SKOS are concepts, lexical
labels, documentation properties (notes), semantic relationships, mapping
properties, and concept collections. (Concepts, concept schemes, and
collections are ontology classes, and the others are ontology properties.) In their
machine-readable form, the SKOS elements are concatenated with no spaces, such
as preLabel, scopeNote, and exactMatch.
SKOS Concepts, Labels, and Notes
SKOS is concept-centric. Making a distinction between concepts
and labels is the biggest departure from traditional thesaurus standards and past
controlled vocabulary practice. A concept is an idea of something, and a label
is a name for that idea. Thus, a concept may have multiple labels. For the
organization of a vocabulary, especially as a hierarchy, one of the various
labels needs to be designated as the preferred displayed label. The others are
alternative labels and its sub-type, hidden label, which may be used to
designate that the label should not display to end-users. Labels for the same concept
may exist in multiple languages, but there may be only one preferred label per
language.
Notation is intended for use as an appending part of a
label, such as an alpha-numeric code, which is commonly used in classification
schemes.
Documentation comprises various types of notes, including scope
note, editorial note, change note, and history note. Definition and example are
additional documentation types. Scope notes are commonly used in thesauri to
clarify the usage of a concept in tagging/indexing for the specific context of
controlled vocabulary and its set of content. They serve an important role for
manual tagging. Other note types may be utilized for administration and
management of the controlled vocabulary. Definitions may be entered for more technical
controlled vocabularies or when the controlled vocabulary also serve the
function of a glossary.
SKOS Concept Schemes and Collections
What constitutes an individual "taxonomy,"
"thesaurus" or other controlled vocabulary? This may not be very clear.
SKOS introduces the formal organizing unit called a concept scheme, as a “collection
of concepts.” A concept scheme is a single controlled vocabulary, thesaurus, hierarchical
taxonomy, facet within a faceted taxonomy, or metadata property within a larger
metadata schema.
There are some advanced, lesser used features of SKOS, including
in scheme, which allows you to control whether a concept is in a concept scheme
regardless of whether it’s within the concept scheme’s hierarchy (which is
otherwise the default). There is also a special designation of top concept for
the top concepts of a concept scheme, a designation which could be utilized for
a front-end display implementation.
Collections are an additional optional way to designate a
grouping of concepts for a purpose, such as the taxonomy concepts to be used in
only specified implementations or those of subject categories for subject
matter expert review. Furthermore, concepts can be ordered within collections.
SKOS Relations and Mapping Properties
SKOS includes what are called semantic relations, although
this name could cause confusion, since they are the basic thesaurus relationships
(broader, narrower, and related), not customizable semantic relations characteristic
of ontologies. These thesaural-type relationships are used between concepts
within the same concept scheme. In addition, SKOS specifies broader transitive
and narrower transitive, meaning the inheritance of the relationship to additional
levels of the hierarchy. This is usually assumed to be the case by default, and
thus these specifically transitive relations are rarely implemented, but if
there are reasons not to inherit and extend the logical hierarchy by default,
then the transitive relations may be used. (I have not come across a use case,
though.)
Since SKOS specifies concept schemes, SKOS also specifies an
additional set of relation types called mapping properties that are to be used
between concepts in different concept schemes or different taxonomies. These comprise exact match, close match, narrower
match, broader match, and related match. Exact match and close match are used
to map existing taxonomies together, often so that one is used in the tagging
and the other is used in the retrieval. The other mapping relations may be used
to extend one taxonomy with another while still maintaining a distinction
between the two.
Following is a table of SKOS elements by type (class or property) with the concatenated machine-readable forms.
Implementation of SKOS
Most commercial and open-source taxonomy/thesaurus
management software now supports SKOS. There are also simple free tools called
SKOS editors. SKOS elements are presented in their full human readable names (such
as Preferred Label, instead of prefLabel), so it is intuitive to understand. Thus,
taxonomists don’t have to worry about SKOS, but should at least be familiar with
its principles. Familiarity with SKOS makes it easier to switch from using one software
package to another. Software may vary, however, in how well they support some
of the less common features, such as in scheme, collections, and broader/narrower
transitive.
Taxonomy/thesaurus management software often has the
additional administrative grouping of related concept schemes for the same
implementation into what may be called a “project” or “knowledge model.” SKOS
mapping relations tend to be used more often across concept schemes that are
managed in different projects, rather than within the same project. Within the
same project, concept schemes tend to represent facets (which have no relations
between them) or ontology classes (which have customized semantic relations
between them).
Since all elements of SKOS are standard machine-readable,
you can leverage any element with rules for usage, such as for how tagging
should be done and how concepts and relationships are displayed. Custom
applications of SKOS vocabularies are thus common.
If you want to dive into all the details of SKOS, consult
these resources from the W3C:
SKOS is intended to be flexible, and it is more suggestive than
restrictive. Thus, a SKOS-based taxonomy or thesaurus could still be poorly designed,
and that’s why the other standards for best practices, ANSI/NISO Z39.19 and ISO
25964 are also important.